開發能夠理解人類語言的計算機
※內容在撰寫本文時是最新的。
基於深度學習的自然語言處理研究
研究大綱

最近,你可能在電視和報紙上聽說過人工智慧和深度學習這兩個詞。 近年來,模仿人類神經網路的多層神經網路的學習研究取得了長足的進步,這些技術被稱為深度學習。 雖然深度學習的理論特徵尚未完全闡明,但人們認為它具有很高的抽象能力,可以自動學習數據的特徵,在圖像識別和語音識別方面,它大大超過了傳統方法的精度,達到了接近人類的分析精度。 在人類語言(自然語言)的分析中,通過深度學習、機器翻譯、對話等方式對語言概念的獲取得到了積極研究,實現了比常規技術更接近人類的自然語言處理。 你們中的許多人可能使用過機器翻譯服務,如谷歌翻譯或DeepL。
我們能夠實現接近人工翻譯的高品質翻譯,但這些服務是通過使用大規模雙語數據和深度學習的機器翻譯技術實現的。 由 OpenAI 開發的 ChatGPT 因其像人類一樣交互而成為全球熱門話題,但這是通過使用由數十億到數千億個參數組成的龐大語言深度學習模型(大型語言模型)以前所未有的規模從自然語言數據中學習來實現的。 我工作的人工智慧實驗室也專注於這些深度學習技術,並正在開展自然語言處理的研究,例如聲譽分析、謂詞表達獲取、專有名稱分析、機器翻譯、情感分析和質量估計。
研究的特點
我們正在研究使用深度學習技術進行自然語言處理。 從廣義上講,它有兩個特點:一是自然語言處理的研究,側重於語言的結構,二是符號接地的研究。
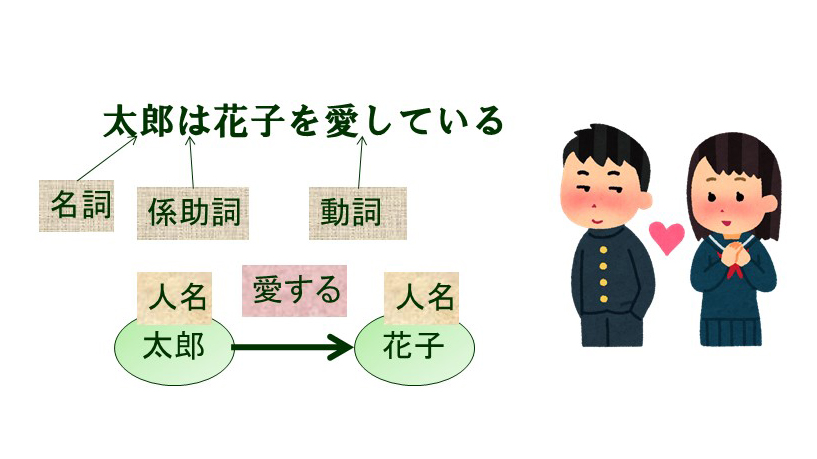
關於第一種語言結構,語言學中詳細討論了語言特有的結構。 例如,有名詞、動詞和形容詞等詞性,人名、地名和公司名稱等專有名詞,考慮這些因素的名詞短語和動詞短語等短語結構,主語、謂語和賓語等術語結構,表達相關關係的代禱結構,以及關係從句和被動語態等各種句法結構(圖 1)。 通過將這些結構的分析與深度學習技術相結合,我們的目標是實現更高性能的自然語言處理。 我們也在進行研究來學習這些結構。 在機器翻譯中,子詞是比單詞短、比字母長的字串,用於輸入,我們正在研究用於機器翻譯的雙語子詞。
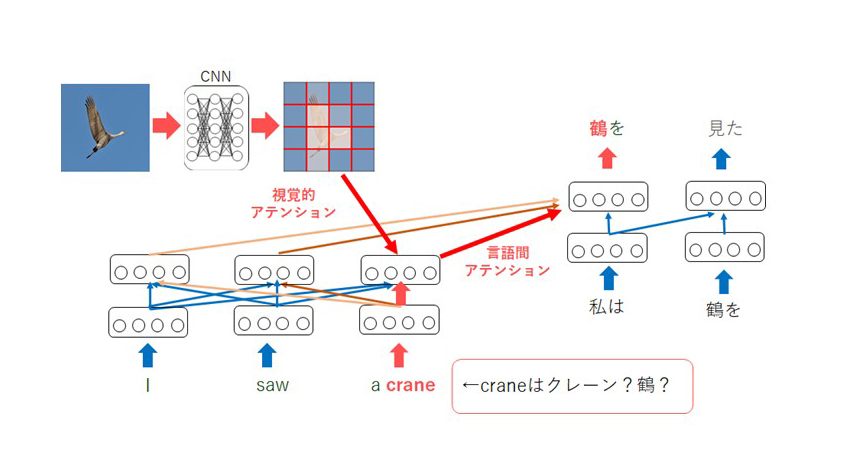
關於第二點,符號接地,傳統的自然語言處理僅使用以文本形式編寫的符號資訊,但為了進行更接近人類的學習,有必要學習符號與現實世界(圖像等)之間的對應關係(符號接地)。 為了實現這些目標,我們正在對多模態機器翻譯進行研究。 目的是通過在執行機器翻譯時提供圖像信息來實現更好的翻譯。 例如,如果有一句話“我看到了一隻起重機”,我不知道“起重機”是“起重機”還是“起重機”。 您將能夠正確翻譯(圖 2)。 此外,機器翻譯使用一種稱為注意力的技術,通過將該技術應用於多模態機器翻譯,可以了解翻譯時要關注圖像的哪個部分。 例如,在翻譯圖 3 中句子中的“man”時,您可以看到翻譯的重點是圖像中的男人。

除此之外,我們還在研究使用深度學習的各種自然語言處理,例如自動摘要、情感分析、複合名稱識別、翻譯品質估計、簡化、語言模型訓練、使用強化學習的機器翻譯以及自動創建英語填空題。
研究的吸引力
首先,目前對人工智慧的研究非常有趣! 歸根結底就是這樣。 2012年左右,深度學習熱潮,即所謂的第三次AI熱潮開始了,但在此之前,人們說人工智慧並不準確,需要很長時間才能實現,而且在我們的有生之年不會實現。 人工智慧已有70多年的歷史,但在過去十年中發展迅速。 傳統智慧被顛覆,新技術層出不窮。 我認為這是目前最令人興奮的研究領域。 在過去,研究“意義”是不可能的(首先不可能回答“意義”是什麼的問題),但現在我們可以看到什麼是意義,我們可以處理上下文。 此外,通過同時學習文本資訊以及圖像等各種模態的資訊,有望實現更接近人類的人工智慧。
未來展望
目前,以ChatGPT為代表的大型語言模型正在經歷前所未有的熱潮。 積極開展其特性的調查和應用研究。 另一方面,大型語言模型非常難以開發,因為它們太大了。 因此,就目前而言,我認為自然語言處理的研究將隨著大型語言模型的小型化和性能化而發展。 除此之外,為了實現更像人類的人工智慧,我相信我們將朝著緊湊的大型語言模型的融合、多模態資訊的融合學習和使用機器人的強化學習的方向發展。
給那些希望做這項研究的人的資訊
過去,創建機器翻譯系統需要幾年時間,但現在已經開發了深度學習工具,可以通過大學的實驗培訓來創建。 如果你對人工智慧、深度學習或自然語言處理感興趣,讓我們一起在愛媛大學學習和研究吧。