인간의 언어를 이해하는 컴퓨터 개발
※게재 내용은 집필 당시의 것입니다.
딥러닝을 이용한 자연어 처리 연구
연구 개요

최근 TV나 신문에서 인공지능, 딥러닝이라는 단어를 자주 접할 수 있을 것이다. 최근 인간의 신경망을 모방한 다층 신경망 학습에 대한 연구가 활발히 진행되고 있으며, 이러한 다양한 기술을 딥러닝이라고 부른다. 딥러닝의 이론적 특성은 아직 충분히 밝혀지지 않았지만, 데이터가 가진 특징을 자동으로 학습하는 높은 추상화 능력을 가지고 있어 이미지 인식이나 음성 인식에서 기존 방법의 정확도를 크게 상회하는 인간에 가까운 분석 정확도를 구현하고 있습니다. 인간이 사용하는 언어(자연어) 분석에서도 딥러닝을 통한 언어 개념 획득, 기계번역, 대화 등이 활발히 연구되고 있으며, 기존 기술보다 훨씬 더 인간에 가까운 자연어 처리가 가능해지고 있습니다. 없으신 분들도 많으시죠?
인간에 의한 번역에 가까운 매우 높은 품질의 번역이 가능하지만, 이러한 서비스는 대규모 대번역 데이터와 딥러닝을 이용한 기계번역 기술을 통해 실현되고 있습니다. 〜수십억~수천억 개의 파라미터로 구성된 거대한 언어용 딥러닝 모델(대규모 언어 모델)을 이용하여 지금까지 없었던 규모의 자연어 데이터로부터 학습함으로써 실현되고 있습니다. 제가 있는 인공지능 연구실도 이러한 딥러닝 기술에 주목하여 평판 분석, 술어 표현 획득, 고유명사 분석, 기계 번역, 감정 분석, 품질 추정 등의 자연어 처리 연구를 진행하고 있습니다.
연구의 특징
딥러닝 기술을 이용한 자연어 처리 연구를 하고 있습니다. 크게 두 가지 특징을 가지고 있는데, 첫 번째는 언어 구조에 주목한 자연어 처리 연구이고, 두 번째는 심볼 그라운딩에 관한 연구입니다.
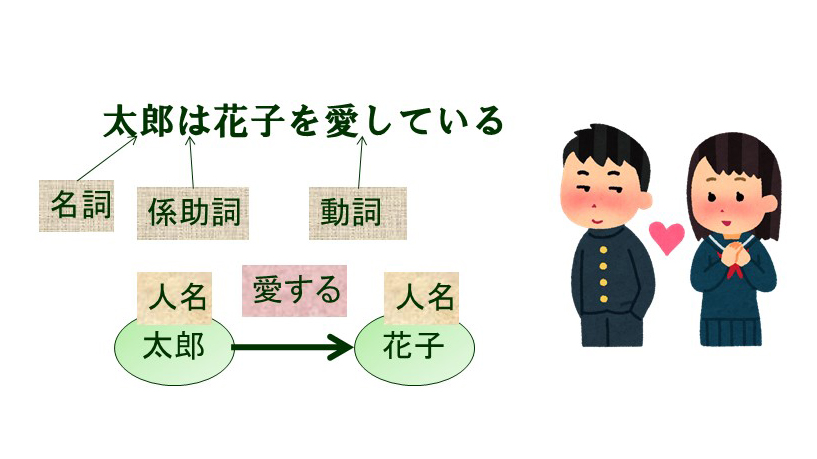
첫 번째는 언어 구조에 대한 것인데, 언어에는 언어학 등에서 정교하게 논의되고 있는 언어 고유의 구조가 있습니다. 예를 들어, 명사, 동사, 형용사 등의 품사, 인명, 지명, 회사명 등의 고유명사, 이를 고려한 명사구, 동사구 등의 구문 구조, 주어, 술어, 목적어 등의 항 구조, 관계 관계를 나타내는 관계수용 구조, 관계절, 수동태 등 다양한 통사 구조가 있습니다(그림 1). 이러한 구조의 분석과 딥러닝 기술을 결합하여 보다 높은 성능의 자연어 처리를 실현하고자 합니다. 또한, 이러한 구조를 역으로 학습하는 연구도 진행하고 있습니다. 기계번역에서는 단어보다 짧고 문자 이상의 길이를 가진 문자열인 서브워드를 입력으로 사용하는데, 기계번역을 위한 이중언어 서브워드를 연구하고 있습니다.
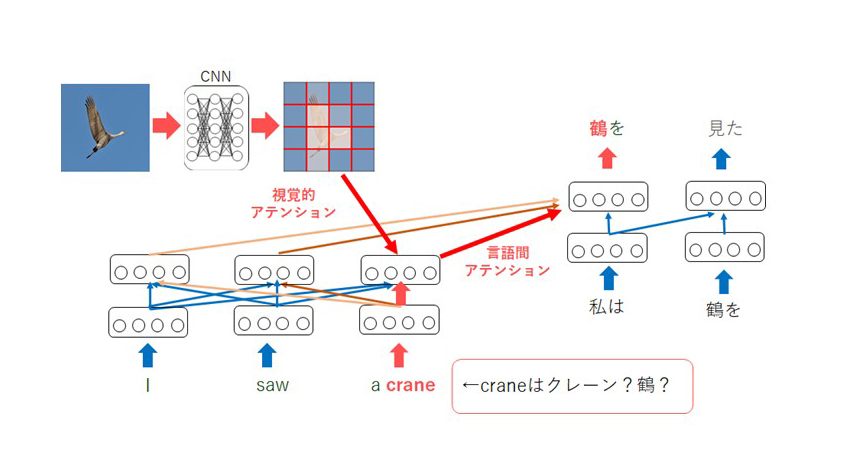
기호 기반 학습에 대해 기존의 자연어 처리는 텍스트에 쓰여진 기호 정보만을 이용해 학습을 진행했지만, 보다 인간에 가까운 학습을 위해서는 기호와 실제 세계(이미지 등)의 대응(기호 기반)을 학습하는 것이 필요하다고 생각됩니다. 입니다. 이를 실현하기 위해 우리는 멀티모달 기계 번역을 연구하고 있다. 기계 번역을 할 때 이미지 정보를 제공하여 더 나은 번역을 구현하는 것이 목적입니다. 예를 들어 “I saw a crane.”이라는 문장이 있을 때, 이대로는 ‘crane’이 ‘크레인’인지 ‘학’인지 알 수 없다. 동시에 이미지를 줄 수 있다면 이러한 모호함이 해소되어 ‘학을 봤다. 라는 식으로 정확하게 번역할 수 있게 된다(그림 2). 또한 기계번역에서는 어텐션(Attention)이라는 기술을 사용하는데, 이 기술을 멀티모달 기계번역에 적용하면 이미지의 어느 부분에 주목하여 번역할 것인지 학습할 수 있다. 예를 들어, 그림 3의 문장에서 ‘man’을 번역할 때, 이미지의 남자에게 주목하여 번역하는 것을 확인할 수 있다.

이 외에도 자동 요약 연구, 감정 분석, 화합물 이름 식별, 번역 품질 추정, 평이화, 언어 모델 학습, 강화학습을 이용한 기계번역, 영어 빈칸 채우기 문제 자동 생성 등 딥러닝을 이용한 다양한 자연어 처리 연구를 진행하고 있습니다.
연구의 매력
우선, 지금의 인공지능이라는 연구가 엄청나게 재미있다! 라는 것을 말씀드리겠습니다. 대략 2012년경부터 딥러닝 붐, 이른바 제3차 인공지능 붐이 시작되었지만, 그때까지만 해도 인공지능이라고 해도 정확도가 낮고 실용화되기까지는 아직 시간이 걸린다, 내가 살아 있는 동안에는 실현되지 않을 것이다, 등의 이야기가 있었습니다. 인공지능의 역사는 70년이 넘었지만, 최근 10년 동안 급속도로 발전했다. 그동안의 상식을 뒤엎고 새로운 기술들이 속속 개발되고 있다. 지금 가장 흥미진진한 연구 분야라고 생각합니다. 예전에는 ‘의미’를 연구하는 것이 불가능했지만(애초에 ‘의미’란 무엇인가라는 질문에 답할 수 없었지만), 이제는 의미 같은 것이 보이고, 맥락도 다룰 수 있게 되었습니다. 또한 텍스트 정보뿐만 아니라 이미지 등 다양한 양식의 정보를 동시에 학습함으로써 보다 인간에 가까운 인공지능을 구현할 수 있을 것으로 기대됩니다.
향후 전망
현재 ChatGPT로 대표되는 대규모 언어 모델이 전례 없는 대세다. 그 특성에 대한 조사와 응용에 대한 연구가 활발히 이루어지고 있습니다. 반면, 대규모 언어모델은 너무 거대하여 개발이 매우 어려운 실정이다. 따라서 당분간은 대규모 언어모델의 소형화, 고성능화에 따라 자연어 처리 연구가 진행될 것으로 생각됩니다. 그리고 더 나아가 보다 인간적인 인공지능을 구현하기 위해 컴팩트한 대규모 언어 모델과 멀티모달 정보의 융합 학습, 로봇을 이용한 강화학습과의 융합으로 나아가지 않을까 생각됩니다.
이 연구를 희망하는 사람들에게 메시지
예전에는 기계번역 시스템을 만드는 데 몇 년이 걸렸지만, 지금은 딥러닝 툴이 정비되어 대학에서 실험 실습으로 만들 수 있을 정도까지 발전했습니다. 인공지능에 관심이 있는 분, 딥러닝에 관심이 있는 분, 자연어 처리에 관심이 있는 분은 꼭 에히메대학교에서 함께 공부하고 연구해 보시기 바랍니다.