Developing a computer that understands human language
※The content is current at the time of writing.
Research on natural language processing using deep learning
Research Overview

Recently, you may have often heard the terms “artificial intelligence” and “deep learning” on television and in newspapers. In recent years, there has been a great deal of research on the learning of multilayer neural networks that mimic the human neural network, and these various technologies are referred to as deep learning. Although the theoretical properties of deep learning have not yet been fully clarified, it is believed to have a high level of abstraction that automatically learns the characteristics of data, and in image and speech recognition, it greatly exceeds the accuracy of conventional methods, achieving analysis accuracy close to that of humans. Many of you may have used machine translation services such as Google Translate or DeepL. Many of you may have used machine translation services such as Google Translate or .
OpenAI’s ChatGPT, which has become a worldwide sensation for its human-like interaction, is made possible by learning from unprecedentedly large amounts of natural language data using a massive deep learning model for languages (large-scale language model) with billions to hundreds of billions of parameters. 〜This is achieved by learning from an unprecedented scale of natural language data using a huge deep learning model for language (large-scale language model) consisting of billions to hundreds of billions of parameters. The Artificial Intelligence Laboratory, where I work, focuses on these deep learning techniques and conducts research on natural language processing such as reputation analysis, predicate acquisition, entity name analysis, machine translation, sentiment analysis, and quality estimation.
Research Features
We conduct research on natural language processing using deep learning techniques. We have two main features: the first is research on natural language processing focusing on language structure, and the second is research on symbol grounding.
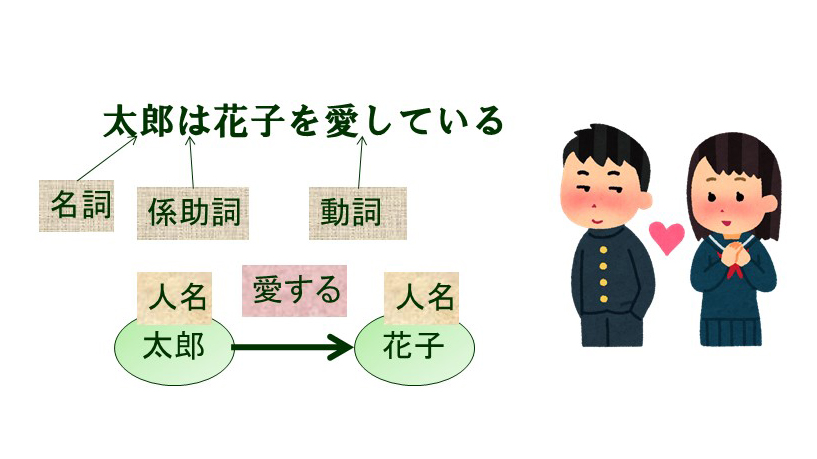
First, there are structures specific to language that are discussed in great detail in linguistics and other fields. For example, there are parts of speech such as nouns, verbs, and adjectives; proper names such as names of people, places, and companies; clause structures such as noun phrases and verb phrases that take these into account; term structures such as subjects, predicates, and objects; and various syntactic structures such as dependency structures, relative clauses, and passive voice (Figure 1). By combining the analysis of these structures with deep learning techniques, we aim to realize natural language processing with higher performance. Conversely, we are also conducting research on learning these structures. In machine translation, subwords, strings of characters that are shorter than words and longer than letters, are used as input, and we are studying bilingual subwords for machine translation.
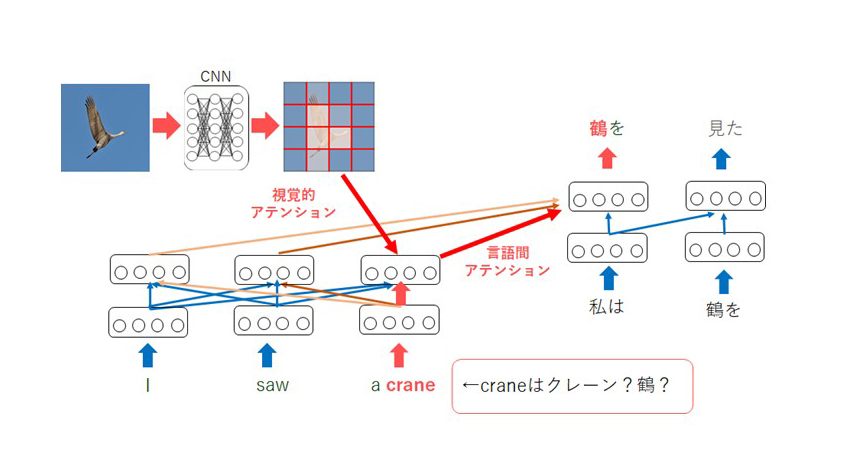
Regarding the second, symbol grounding, conventional natural language processing uses only symbolic information in text to learn, but for more human-like learning, it is considered necessary to learn the mapping between symbols and the real world (e.g., images) (symbol grounding) We are working toward the realization of these goals. Toward the realization of these goals, we are studying multimodal machine translation. The goal is to achieve better translation by providing image information when performing machine translation. For example, if the sentence “I saw a crane.” is given, it is not clear whether “crane” is a “crane” or a “crane. If we can provide an image at the same time, these ambiguities can be resolved and the sentence can be correctly translated as “I saw a crane.” (Figure 2). By applying this technology to multimodal machine translation, it is possible to learn which parts of the image to focus on for translation. For example, when translating the word “man” in the sentence in Figure 3, we can confirm that the translation focuses on the man in the image.

In addition to these, we are also conducting research on automatic summarization, sentiment analysis, compound name identification, translation quality estimation, plain language translation, learning language models, machine translation using reinforcement learning, automatic creation of English fill-in-the-blank questions, and various other natural language processing using deep learning.
Research Attraction
First of all, the current research on artificial intelligence is incredibly interesting! This is what I would like to say. Until then, it was said that artificial intelligence was not very accurate, that it would take a long time to become practical, and that it would not be realized in our lifetime. Artificial intelligence has a history of more than 70 years, but it has developed rapidly during this last mere decade. Conventional wisdom has been overturned and new technologies have been developed one after another. I think this is the most exciting research area right now. In the past, it was impossible to study “meaning” (it was impossible to answer the question of what “meaning” was in the first place), but now we can see something that looks like meaning, and we can handle context as well. Furthermore, by learning not only textual information but also information from various modalities such as images at the same time, it is expected to realize artificial intelligence that is closer to humans.
Future Outlook
Large-scale language models such as ChatGPT are currently experiencing an unprecedented boom. Research on their properties and their applications is being actively conducted. On the other hand, large-scale language models are too large to be developed. For this reason, I believe that for the time being, research on natural language processing will progress along the path of miniaturization and performance improvement of large-scale language models. Beyond that, I believe that we will move toward fusion learning of compact large-scale language models with multimodal information and reinforcement learning using robots in order to achieve more human-like artificial intelligence.
Message to those who are interested in this research
In the past, it took several years to create a machine translation system, but now deep learning tools have been developed to the point where it can be created in university experimental training. If you are interested in artificial intelligence, deep learning, or natural language processing, please join us at Ehime University to study and research together.