



人間の言葉を理解するコンピュータの開発
※掲載内容は執筆当時のものです。
深層学習を用いた自然言語処理の研究
研究の概要

最近、テレビや新聞で人工知能や深層学習という言葉を耳にすることがよくあるのではないでしょうか。近年、人間の神経網を模した多層ニューラルネットワークの学習に関する研究が大きく進み、これらの諸技術は深層学習と呼ばれています。深層学習の理論的特性はまだ十分には明らかになっていませんが、データが持つ特徴を自動的に学習する高い抽象化の能力を持っていると考えられていて、画像認識や音声認識において、従来手法の精度を大きく上回り、人間に近い解析精度を実現しています。人間が用いる言語(自然言語)の解析においても、深層学習による言語概念の獲得や機械翻訳、対話等が盛んに研究されており、従来技術よりも人間にかなり近い自然言語処理が実現できています。Google翻訳やDeepL等の機械翻訳サービスを使ったことがある方も多いのではないでしょうか。
人間による翻訳に近い非常に高品質な翻訳ができていますが、これらのサービスは、大規模対訳データと深層学習を用いた機械翻訳技術によって実現されています。OpenAIが開発したChatGPTは、人間のように対話をすることから世界中で話題となっていますが、これは数十億〜数千億パラメータから成る巨大な言語用深層学習モデル(大規模言語モデル)を用い、今までにない規模の自然言語データから学習することで実現されています。私のいる人工知能研究室もこれらの深層学習技術に注目し、評判分析、述語表現獲得、固有名解析、機械翻訳、感情分析、品質推定等の自然言語処理の研究を行っています。
研究の特色
深層学習技術を用いた自然言語処理の研究を行っています。大きく分けると2つの特色を持っていて、一つ目は、言語構造に注目した自然言語処理の研究で、もう一つはシンボルグラウンディングに関する研究です。
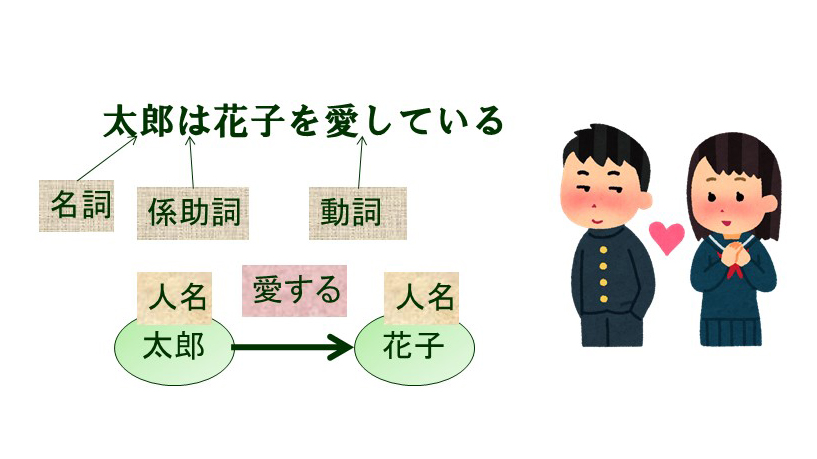
一つ目の言語構造についてですが、言語には言語学などで精緻に議論されている言語特有の構造があります。例えば、名詞、動詞、形容詞といった品詞であったり、人名、地名、会社名といった固有名、それらを考慮した上の名詞句、動詞句などの句構造や、主語、述語、目的語といった項構造、係り受け関係を表す係り受け構造、関係節や受動態などの様々な統語構造があります(図1)。これらの構造の解析と深層学習技術を組み合わせることによって、より性能の高い自然言語処理の実現を目指しています。また、逆にこれらの構造を学習する研究も行っています。機械翻訳においては、サブワードと呼ばれる、単語よりも短く、文字以上の長さの文字列が入力に用いられていますが、機械翻訳のためのバイリンガルなサブワードの研究を行っています。
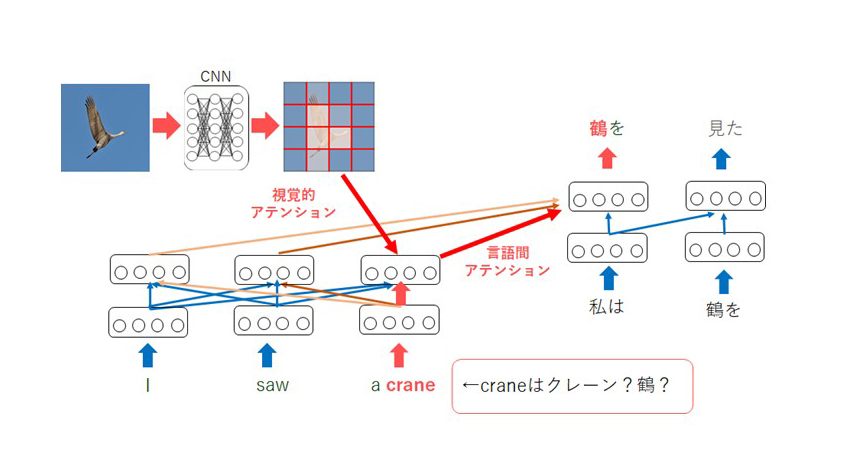
2つ目のシンボルグラウンディングについて、従来の自然言語処理はテキストに書かれた記号情報だけを用いて学習を行っていましたが、より人間に近い学習を行うためには、記号と実世界(画像など)の対応付け(シンボルグラウンディング)を学習することが必要だと考えられています。これらの実現に向けて、我々はマルチモーダル機械翻訳の研究を行っています。機械翻訳を行う際に画像情報を与えることでより良い翻訳を実現することが目的となっています。例えば、「I saw a crane.」という文があったとき、このままでは「crane」は「クレーン」なのか「鶴」なのかわかりません。同時に画像を与えることができればこれらの曖昧性が解消されて、「鶴を見た。」というふうに正しく翻訳できるようになります(図2)。また、機械翻訳ではアテンションと呼ばれる技術が用いられますが、その技術をマルチモーダル機械翻訳に適用することで、画像のどこの部分に注目して翻訳するか学習することができます。例えば、図3の文の「man」を翻訳するときには、画像の男に注目して翻訳していることが確認できます。

これら以外にも、自動要約の研究や、感情分析、化合物名の同定、翻訳の品質推定、平易化、言語モデルの学習、強化学習を用いた機械翻訳、英語穴埋め問題の自動作成など、深層学習を用いた様々な自然言語処理の研究を行っています。
研究の魅力
まずは、今の人工知能という研究がとんでもなく面白い!ということにつきます。おおよそ2012年頃から深層学習ブーム、いわゆる第3次AIブームが始まりましたが、それまでは人工知能といっても、精度が低くて実用的になるにはまだまだ時間がかかる、生きているうちには実現しないだろう、などと言われていました。人工知能の歴史は70年以上ありますが、この最後のわずか10年の間に急速に発展しました。それまでの常識が覆され、新しい技術が次々と開発されています。今最もエキサイティングな研究領域だと思います。昔は「意味」の研究なんてとてもできないものでしたが(そもそも「意味」とは何かという問いに答えられない)、今は意味らしきものが見えてきて、文脈も扱えるようになってきました。さらにテキスト情報だけでなく、画像など様々なモダリティの情報も同時に学習することで、より人間に近い人工知能の実現が期待されています。
今後の展望
現在ChatGPTに代表される大規模言語モデルが空前の大ブームです。その特性の調査や応用に関する研究が盛んに行われています。一方、大規模言語モデルは巨大すぎるため開発することが非常に難しい状況です。そのため、当面大規模言語モデルの小型化・高性能化に沿って自然言語処理の研究が進むのではないかと思っています。さらにその先には、より人間らしい人工知能を実現するために、コンパクトな大規模言語モデルとマルチモーダル情報の融合学習、ロボットを用いた強化学習との融合に向かっていくのではないかと考えています。
この研究を志望する方へのメッセージ
昔は機械翻訳のシステムを作るのに数年がかりでしたが、今は深層学習ツールが整備されて大学の実験実習で作成できるまでになっています。人工知能に興味のある方、深層学習に興味のある方、自然言語処理に興味のある方は是非愛媛大学で一緒に勉強し、研究をしましょう。