



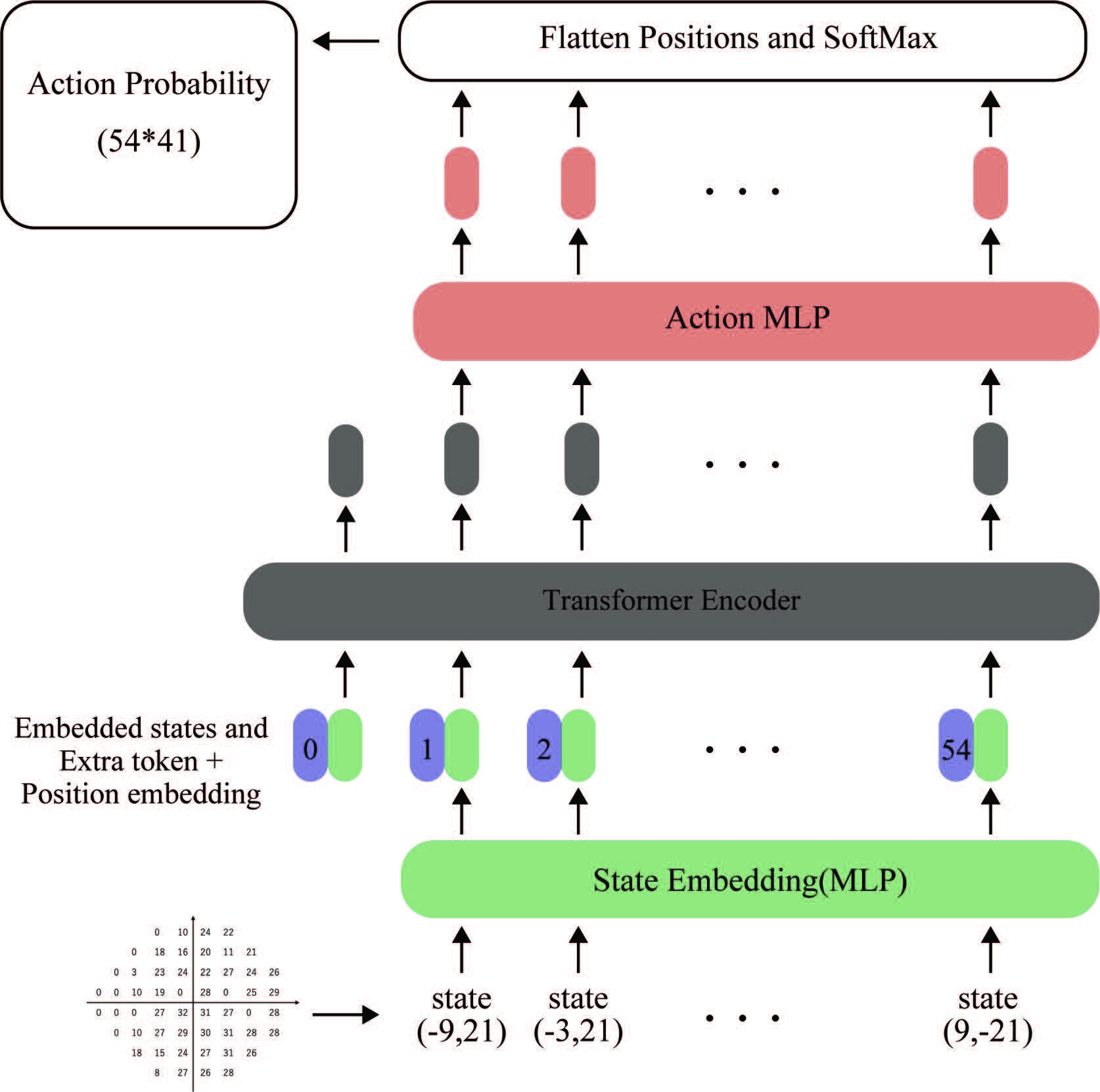
視野検査は視野欠損を伴う疾患に対して実施される検査です。視野検査は被検者の負担が大きく、より短い時間で正確に検査することが求められています。愛媛大学総合情報メディアセンターの佐伯昌造特定研究員らによる本研究では、この視野検査を制御する視野検査AIのViFT(Visual Field Transformer)を深層強化学習するフレームワークの構築を行いました。このフレームワークでは、ViFTを学習するために、検査中の人の反応の不確かさをモデル化した視野検査シミュレーションを用いて深層強化学習を行いました。今まで人手で設計していた視野の空間的な関係を、ViFTは深層強化学習の過程でデータから学習します。その結果、ViFTは従来の手法と比較して半分以下の時間で同等以上の精度で検査が実施可能であることを示しました。
研究のポイント
- 視野検査を制御するエージェントの学習フレームワークを確立した
- 人の光への反応の不確かさを考慮した視野検査シミュレータを用いることによって、多様な人への検査がロバストに学習できる
- デファクトスタンダードで用いられている従来の検査アルゴリズムと比較して、半分以下の検査時間で同等以上の検査精度を達成した
論文情報
掲載誌:Medical Image Analysis
題名:ViFT: Visual field transformer for visual field testing via deep reinforcement learning
(和訳)深層強化学習による視野検査のための視野トランスフォーマ
著者:Shozo Saeki, Minoru Kawahara, Hirohisa Aman
DOI:10.1016/j.media.2025.103721
本件に関する問い合わせ先